




Jim Elvidge holds a Master's Degree in Electrical Engineering from Cornell University. He has applied his training in the high-tech world as a leader in technology and enterprise management, including many years in executive roles for various companies and entrepreneurial ventures. He also holds 4 patents in digital signal processing and has written articles for publications as diverse as Monitoring Times and the IEEE Transactions on Geoscience and Remote Sensing. Beyond the high-tech realm, however, Elvidge has years of experience as a musician, writer, and truth seeker. He merged his technology skills with his love of music, developed one of the first PC-based digital music samplers, and co-founded RadioAMP, the first private-label online streaming-radio company. For many years, Elvidge has kept pace with the latest research, theories, and discoveries in the varied fields of subatomic physics, cosmology, artificial intelligence, nanotechnology, and the paranormal. This unique knowledge base has provided the foundation for his first full-length book, "The Universe-Solved!"
Website: http://www.theuniversesolved.com/
DNA is a self-replicating nucleic acid that supposedly encodes the instructions for building and maintaining cells of an organism. With an ordered grouping of over a billion chemical base pairs, which are identical for each cell in the organism, the unique DNA for a particular individual resembles statements in a programming language. This concept is not lost on Dr. Stephen Meyer (Ph.D., history and philosophy of science, Cambridge University), who posits that the source of information must be intelligent and therefore DNA, as information, is evidence of Intelligent Design. He argues that all hypotheses that account for the development of this digital code, such as self-organization and RNA-first, have failed. In a well-publicized debate with Dr. Peter Atkins (Ph.D., theoretical chemistry, University of Leicester), a well-known atheist and secular humanist, Atkins counters that information can come from natural mechanisms. Unfortunately, Atkins resorts to insults and name calling, so the debate is kind of tainted, and he never got a chance to present his main argument in a methodical manner. But it raised some very interesting questions, which I don’t think either side of the argument has really properly addressed.
Violation of the Second Law of Thermodynamics?
Intelligent Design advocates trot out the Second Law of Thermodynamics and state that the fact that simple molecules can’t self-replicate without violating that Law proves Intelligent Design. But it doesn’t really. The Second Law is the idea that the total disorder of a system, e.g. the universe, always increases. Or that heat always flows from hot to cold. It’s why coffee always gets cold, why money seems to dissipate at a casino, why time flows forward, why Murphy had a law, and why cats and dogs don’t tend to clean up the house. However, the law applies to the whole system, including many instances of increased disorder weighed against the fewer instances of increased order. In other words, while there are distinct probabilities of isolated cases of increasing order, those probabilities are outweighed by the cases of decreasing order. It is not unlike the wave function distribution of quantum mechanical states. There is a finite probability that electrons will pass through normally impenetrable boundaries. In fact, this tunneling effect is what enables some semiconductors to perform their functions, so we know that the effect is real. However, in the majority of cases, the particle will be stopped by the barrier, just as in the majority of cases of a closed system, entropy will increase. In summary, disorder tends to increase, but that doesn’t mean that there can’t be isolated examples of increased order in the universe. That seems to leave the door open to the possibility that one such example might be the creation of self-replicating molecules.
Another point of contention in this “origin of life” debate relates to the nature of information, such as DNA. Meyer’s case is weak if he is making a blanket assertion that information can only come from intelligence. I could argue that, given a long enough period of time, if you leave a typewriter outdoors, hailstones will ultimately hit the keys in an order that creates recognizable poetry. So the question boils down to this – was there enough time and proper conditions for evolutionary processes to create the self-replicating DNA molecule from non-self replicating molecules necessary for creating the mechanism for life?
Doing the Math
The math doesn’t look good for the atheists. Francis Crick, molecular biologist, physicist, and Nobel Prize winner for the discovery of DNA, once commented on the miracle of constructing a single protein from evolutionary combinatorial selection: “all the cell need do is to string together the amino acids (which make up the polypeptide chain) in the correct order. This is a complicated biochemical process, a molecular assembly line, using instructions in the form of a nucleic acid tape (the so-called messenger RNA). Here we need only ask, how many possible proteins are there? If a particular amino acid sequence was selected by chance, how rare of an event would that be?… the number of possibilities is twenty multiplied by itself some two hundred times. This is conveniently written 10E260, that is a one followed by 260 zeros!” [1]
Dr. Robert L. Piccioni, Ph.D., Physics from Stanford says that the odds of 3 billion randomly arranged base-pairs matching human DNA is about the same as drawing the ace of spades one billion times in a row from randomly shuffled decks of cards.
Dr. Harold Morowitz, a renowned physicist from Yale University and author of Origin of Cellular Life (1993), declared that the odds for any kind of spontaneous generation of life from a combination of the standard life building blocks are one chance in 10E100000000000 (you read that right, that’s 1 followed by 100,000,000,000 zeros). [2]
Famed British Royal Astronomer Sir Fred Hoyle proposed that such odds were one chance in 10E40000, or roughly “the same as the probability that a tornado sweeping through a junkyard could assemble a 747.” [3]
By the way, scientists generally set their “Impossibility Standard” at one chance in 10E50 (1 in a 100,000 billion, billion, billion, billion, billion). So, it seems that the likelihood of life forming via combinatorial chemical evolution is, for all intents and purposes, zero.
Other Ideas
Perhaps discouraged by the straight combinatorial odds against life forming, scientists have ratcheted up the creative thinking and come up with some interesting new ideas that could explain how life formed naturally from the primordial soup. One such idea, explored by Michael Yarus of the University of Colorado at Boulder, and validated by David Johnson and Lei Wang of the Salk Institute for Biological Sciences in La Jolla, California, is that certain RNA building blocks (amino acids and nucleotides) have a chemical affinity for one another. This affinity tends to line up the right molecules to form self-replicating chains of RNA, which led to the formation of DNA and life. [4] Essentially, this idea changes the odds that we discussed above. Instead of purely random associations of life’s building blocks, we would be dealing with less than random processes. But how much less than statistical randomness is the million-dollar question. Slightly less, and we still have a massive improbability. Significantly less, and perhaps life could have formed naturally.
DNA as a Program?
My interest in this goes beyond this specific debate. I have a hobby of collecting evidence that our reality is programmed. My book “The Universe – Solved!”, is chock full of such evidence. Clearly, if DNA is data as Dr. Meyer suggests, that data may be either the result of, or the input to, a program. If so, it is at a very high level. By that I refer to the level of hierarchical programming.
When you build a house, you don’t start with raw materials, like trees, metal, and plastic. Instead, you have building blocks – windows, 2x4s, pieces of plywood, concrete, tiles, wallboard, shingles, nails, etc. So it is with programming. It is much easier to use, write, and understand a program that consists of building blocks than a “linear” program that has, for example, 42,000 sequential lines of code. In the building blocks for the house, some components, such as a sink, are themselves composed of other building blocks (bowl, plumbing, faucet). Similarly, software may consist of building blocks, which are composed of smaller building blocks. Such programming is called hierarchical programming. The basic rules are that the lower the layer (toward the bottom of the chart), the more fundamental the operation. The bottom layer of the chart would typically be “atomic” operations that any higher layer function can use. For convention, let’s refer to this lowest layer of functions as Level 1. The higher you go on the chart, the more “sophisticated” the operation is. Creating a set of virtual doors, for example, is a much more sophisticated and higher layer function than drawing a point, and might be a Level 5 function or so. Also, no function on any layer calls, or makes use of, another function on that layer; rather, they use lower layer functions to build up their capabilities. Outlining a good hierarchy would consist of ensuring that each function at a particular layer is roughly comparable in terms of sophistication. A function called AddTree should be at the same layer as AddCloud, for example, while AddForest and CreateSky would each be at the next layer up.
If our reality is, in any sense, programmed, then the lowest layers of the program must be below our current ability to observe. That is, the objects that are under programmatic control have to be smaller and more fundamental than subatomic particles. Currently, we can make physical observations of items as small as electron clouds around carbon atoms, which are on the order of 10E-10 meters. We can infer from high-energy experiments, such as those in progress at the Linear Hadron Collider at Cern, deeper details about the structure of the nucleus and subatomic particles. From those experiments, we can infer structures down to 10E-16 meters, at the level of quarks. At some point, in a programmed reality, all structure is simply information. It is interesting to speculate about where that might occur on the spatial scale.
One logical point could be at the Planck level, or 10E-35 meters. This is the granularity of space, according to physicists. The figure below shows how the position of a point in space can be determine ever more accurately as you zoom in on the region of space, effectively continuously increasing the magnification. Were space truly continuous, there would be no limit to how far you could zoom; there would always be space between any two points on which you could zoom further. However, physicists tell us that when you zoom in to the scale of 10E-35 meters, something really strange happens. It becomes impossible to position this object or point between two Planck lengths (1.6 x 10E-35 meters) because nothing exists there. In fact, space does not even exist between two adjacent points separated by the Planck length. It is sort of analogous to your TV or computer screen. From a distance, you see a nice continuous image. But, when you get close up, you see that the image is nothing but a bunch of dots at discrete positions on the screen and there is actually no part of the image in between two adjacent dots. We therefore say that rather than being continuous, space is discrete, granular, or quantized. At this point, our object under measurement can only be exactly at one of those positions.
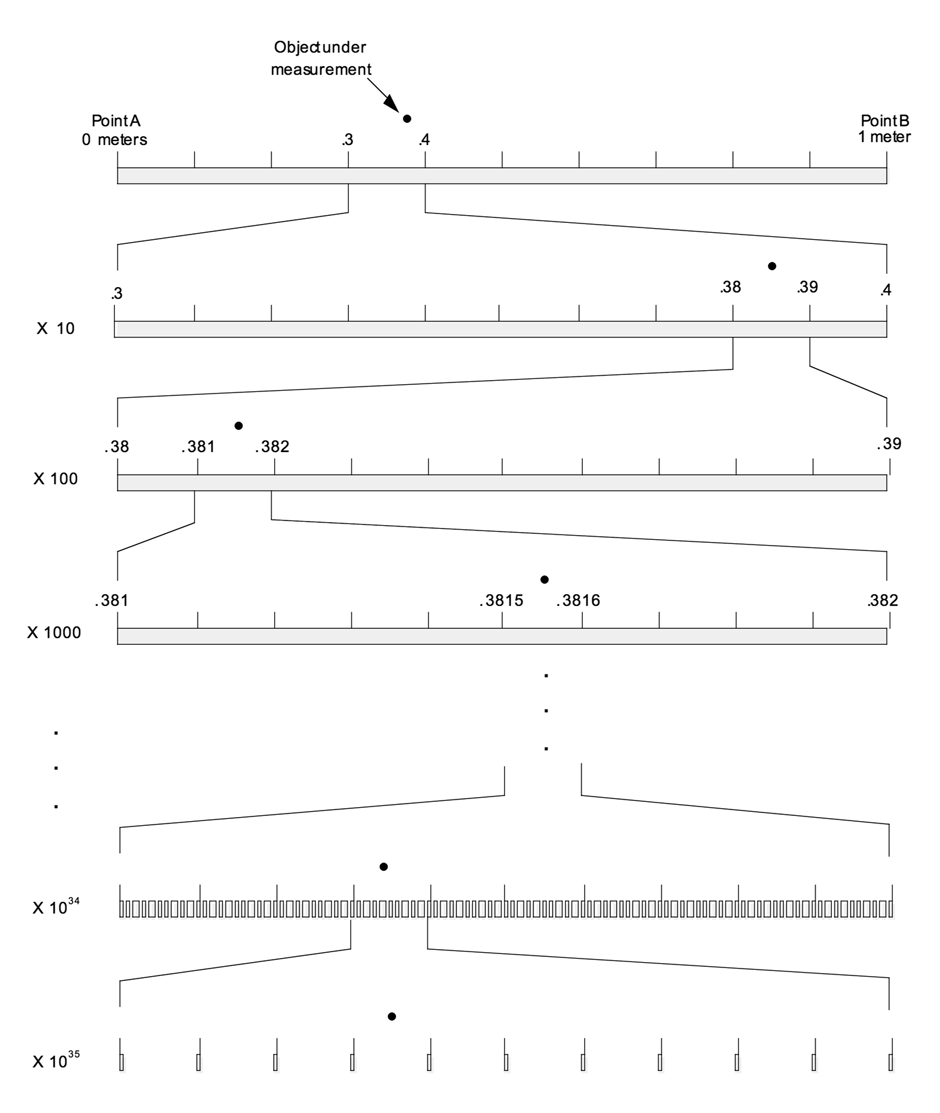
So, it is possible that the pure informational structure of space begins at the Planck level. That would mean that the “program” is controlling information at that fine of a resolution. Of course, it could even be finer than that. The quantum mechanical strangeness found at the Planck level may simply be due to the physics of the program, unattainable to our perception due to these laws, while reality is actually constructed at an even deeper level. Alternatively, the physical laws that cause quantum mechanical properties may be just rules of the program, whereas the granularity of reality is courser than the Planck level. All of these three options are possible in a programmed reality. All we really know is that it is currently beyond our capacity to resolve. In any case, the informational content of reality is deeper than the base pairs on DNA strands. But it doesn’t mean that information can’t exist in a higher level construct, just as cells in a spreadsheet contain data, but the presentation of that spreadsheet is done by a program at a much deeper level. The question is whether or not the information contained in the DNA code is indicative of intelligence. Is there some sort of “signature” or “watermark” in the code? Some evidence of intelligence that has nothing to do with the functioning of the molecule? So far, there isn’t, but that doesn’t mean we shouldn’t be looking for it.
References:
- Crick, Francis. Life Itself, Its Origin and Nature. Simon and Schuster; 1st edition. 1981. pp 51-52.
- Hoyle, Sir Fred. Nature, vol. 294:105, November 12, 1981.
- Morowitz, Harold J. Energy Flow in Biology. Academic Press, 1968.
- Brahic, Catherine. “Self-starter: Life got going all on its own” New Scientist, 21 April 2010.